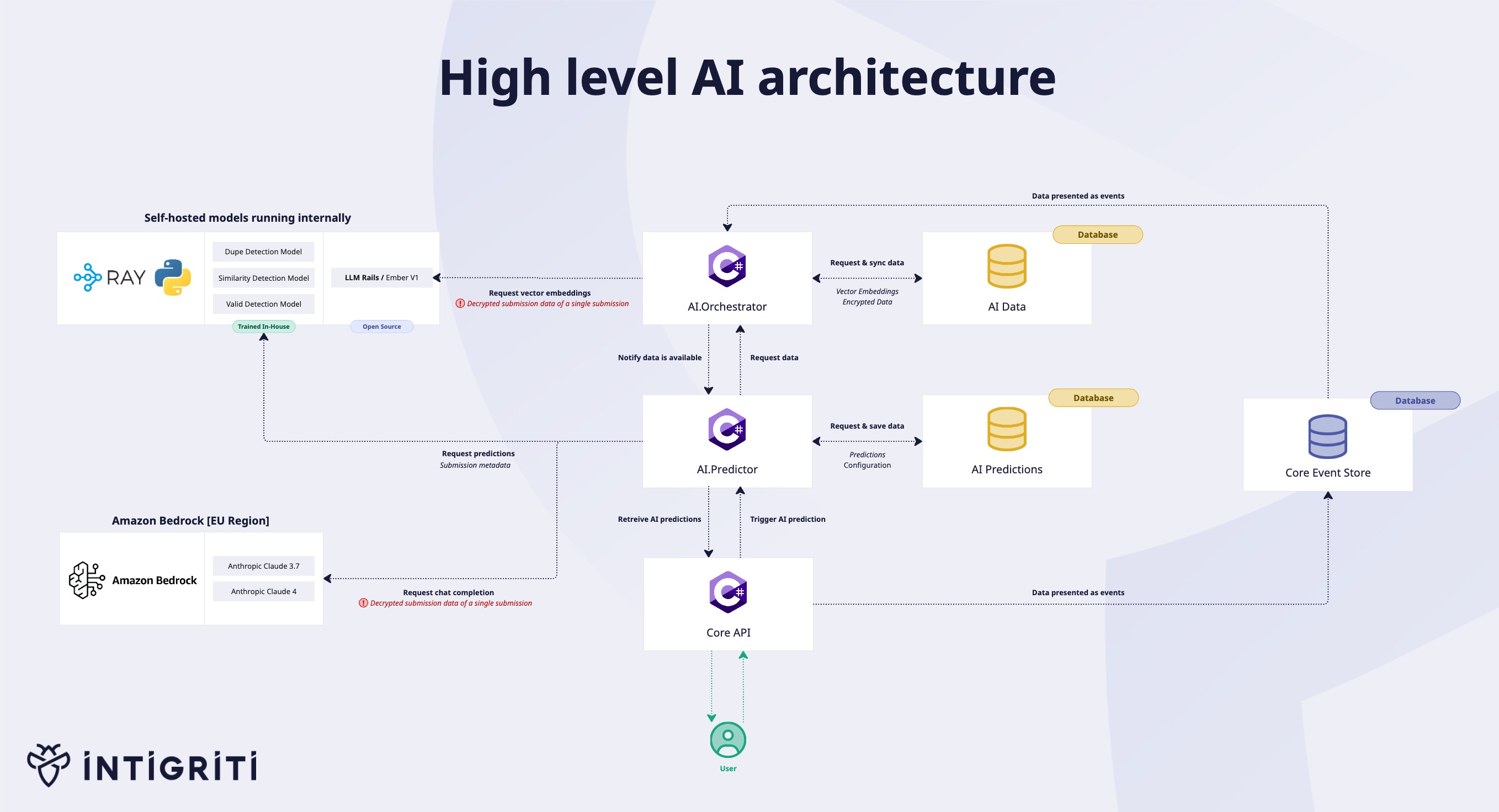
This section describes the AI-powered features available within the Intigriti platform.
Submission Summarization
Submission Summarization is an AI feature that takes the contents of a single submission and generates a well-structured summary in a specific format. The feature is designed to help both customers and the Triage Team to quickly understand the context of a submission.
Architecture and Data
This model uses an LLM from the Anthropic Claude family with a specialized system and user prompt to generate a well-structured summary. Only the context of the current submission is provided to the model. The model is not trained on any customer data.
Performance Metrics
The model's performance is measured by human reviewers and standard metrics (ROUGE, BLEU) on internal test sets.
Intended Use
This feature is available to the internal Triage Team and customers with the AI feature flag enabled to streamline operations and decision making.
Submission Skill Labeling
Submission Skill Labeling is an AI feature that identifies the used skill for creating a submission.The feature is designed to facilitate required skill suggestions on an asset.
Architecture and Data
This model uses an LLM from the Anthropic Claude family with a specialized system and user prompt to predict the used skill. Only the context of the current submission is provided to the model. The model is not trained on any customer data.
Performance Metrics
The model's performance is measured by human reviewers and standard metrics (ROUGE, BLEU) on internal test sets.
Intended Use
This feature is available directly to the internal Triage Team. The data is also used to show required skill suggestions on company assets towards customers.
Submission Dupe Detection
Submission Dupe Detection is an AI feature that identifies potential duplicate submissions within the same program and company. The feature is designed to help the Triage Team spot duplicate submissions and reduce the amount of time it takes to review and act on these reports.
Architecture and Training Data
This model utilizes an in-house XGBoost binary classification model, trained on anonymized submission pairs that are labeled (duplicate vs. non-duplicate). It combines similarity scores derived from text embeddings with categorical data to identify if a submission is a potential duplicate.
The model is trained on the following data:
- Title Similarity
- Endpoint / Vulnerable Component Similarity
- Asset Name Similarity
- Company Asset Equality
- Company Asset Type Equality
- Type Equality
- Type Category Equality
- Severity Equality
- Researcher Equality
- Program Equality
- Created At Delta (difference in creation time)
We do not train on data of companies that have the AI Feature Flag disabled.
Performance Metrics
The model's performance is measured by the following metrics:
- Accuracy: 95% of correct duplicate vs. non-duplicate classifications.
- Precision / Recall / F1-Score / Cross-Validation: Reflects the trade-off between false positives and false negatives.
The XGBoost model is re-trained every 6 months on resolved submissions, during which the accuracy and metrics are re-evaluated.
Intended Use
This feature is only available to the internal Triage Team to streamline operations and decision making. All decisions are still owned by a human triager. The AI features serve to enhance productivity and guide decision making.
Submission Similarity Detection
Submission Similarity Detection is an AI feature that identifies potential similar submissions within the same program and company. The feature is designed to help the Triage Team spot recurring resolved or rejected submissions.
Architecture and Training Data
This model utilizes an in-house XGBoost binary classification model, trained on anonymized submission pairs that are labeled (similar vs. non-similar). It combines similarity scores derived from text embeddings with categorical data to identify if a submission is a similar submission.
The model is trained on the following data:
- Title Similarity
- Endpoint / Vulnerable Component Similarity
- Asset Name Similarity
- Company Asset Equality
- Company Asset Type Equality
- Type Equality
- Type Category Equality
- Severity Equality
We do not train on data of companies that have the AI Feature Flag disabled.
Performance Metrics
The model's performance is measured by the following metrics:
- Accuracy: 95% of correct similar vs. non-similar classifications.
- Precision / Recall / F1-Score / Cross-Validation: Reflects the trade-off between false positives and false negatives.
Intended Use
This feature is only available to the internal Triage Team to streamline operations and decision making. All likely valid submissions are still verified manually by a human triager, with the AI feature serving purely to enhance productivity.
Submission Out-of-scope detection
Submission Out of Scope Detection is an AI feature that identifies if a given submission is out of scope, according to the program out of scope guidelines. The feature is designed to help the Triage Team spot out of scope submissions and reduce the amount of time it takes to review and act on these reports.
This model uses an LLM from the Anthropic Claude family with a specialized system and user prompt to detect if a submission is out of scope and which out of scope rule has been matched. Only the context of the current submission, program in scope and out of scope rules are provided to the model. The model is not trained or fine-tuned on any customer data.
Performance Metrics
The model's performance is measured by human reviewers and standard metrics (ROUGE, BLEU) on internal test sets.
Intended Use
This feature is only available to the internal Triage Team to streamline operations and decision making. All decisions are still owned by a human triager. The AI features serve to enhance productivity and guide decision making.
Submission Suggestions
Submission Suggestions is an AI feature generates on demand and automated title and endpoint suggestions, based upon the triage guidelines and data about the current submission.
Architecture and Data
This model uses an LLM from the Anthropic Claude family with a specialized system and user prompt to generate a well-structured title or endpoint. Only the context of the current submission, program in scope and out of scope rules are provided to the model. The model is not trained or fine-tuned on any customer data.
Performance Metrics
The model's performance is measured by human reviewers and standard metrics (ROUGE, BLEU) on internal test sets.
Intended Use
This feature is only available to the internal Triage Team to streamline operations and decision making. All submissions are still verified manually by a human triager, with the AI feature serving purely to enhance productivity.
Program Impact Generator
The program impact report generator is a tool designed to help Customer Success Managers lead impactful conversations with customers about how Intigriti contributes to their security posture.
Architecture and Data
This model uses an LLM from the Anthropic Claude family with a specialized system and user prompt to generate a well-structured report. Only the context of a set of selected submissions and program description are provided to the model. The model is not trained or fine-tuned on any customer data.
Performance Metrics
The model's performance is measured by human reviewers and standard metrics (ROUGE, BLEU) on internal test sets.
Intended Use
This feature is only available to the internal Customer Success team to help them understand technical submissions and lead conversations with customers.
Submission Valid Detection
Submission Valid Detection is an AI feature that predicts whether a submission is valid or not with a given probability. The feature is designed to help the Triage Team identify potentially invalid submissions and reduce the amount of time it takes to review and act on these reports.
Architecture and Training Data
This model utilizes an in-house XGBoost binary classification model, trained on anonymized submission data that are labeled (valid vs. invalid). It combines various submission features and metadata, including structural characteristics, content metrics, severity and type information, historical submission patterns, and contextual data to predict submission validity.
We do not train on data of companies that have the AI Feature Flag disabled.
Performance Metrics
The model's performance is measured by the following metrics:
- Accuracy: 79% of correct valid vs. invalid classifications.
- Precision / Recall / F1-Score / Cross-Validation: Reflects the trade-off between false positives and false negatives.
Most misclassifications occur with informative submissions being classified as "valid" (typically with low probability). This is because those submissions are primarily informative based on content rather than structural or quality characteristics.
Intended Use
This feature is only available to the internal Triage Team to streamline operations and decision making. All likely valid submissions are still verified manually by a human triager, with the AI feature serving purely to enhance productivity.
Researcher Recommendation
Researcher Recommendation is an AI feature that recommends suitable programs to researchers on their dashboard. The feature is designed to help researchers discover programs that match their skills, interests, and past performance, making it easier to find relevant opportunities.
Architecture and Training Data
This model utilizes an in-house two-tower dual encoder neural network built with Keras/TensorFlow, trained on anonymized researcher-program pairs. The dual encoder architecture independently processes researcher and program features before computing compatibility scores. It combines various features and metadata from both researchers and programs, including researcher profile information, historical submission patterns, payout data, program characteristics, and bounty information to predict program suitability for each researcher.
Performance Metrics
The model's performance is measured by the following metrics:
- Accuracy: 85% of correct program recommendation classifications.
- Precision / Recall / F1-Score: Reflects the model's ability to recommend relevant programs to researchers.
- Cross-Validation: Ensures model generalization across different researcher segments.
Intended Use
This feature is available to researchers on the researcher dashboard to help them discover programs that align with their skills and interests. The recommendations serve to enhance researcher engagement and program discovery.
This feature is currently in BETA and is being gradually rolled out to all researchers.
Triage Agent
The Triage Agent is an LLM-based AI feature designed to support the internal Triage Team in streamlining operations and decision making when reviewing incoming submissions.
Architecture and Data
This model uses an LLM from the Anthropic Claude family via Google Cloud Vertex with a specialized system and user prompt to assist in triage decisions. The agent has access to tools for retrieving program and submission data within the same organisation, as well as public researcher profile information. The model is not trained or fine-tuned on any customer data.
Performance Metrics
The model's performance is measured by human reviewers and standard metrics (ROUGE, BLEU) on internal test sets. An evaluation dataset of generated submissions is used to validate the model's accuracy.
Intended Use
This feature is only available to the internal Triage Team to streamline operations and support decision making. All submissions are still verified by a human triager, with the AI feature serving purely to enhance productivity.